
这是任务调度系统调研系列文章的开篇,后续会陆续调研Oozie,Azkaban,Dolphin Scheduler等系统。本文的主要内容是来自对官方文档和网上相关资料的调研,并非基于实际使用的经验总结,文章中难免会有一些不尽的细节或者关于Airflow错误的观点,如有不当之处,欢迎指正交流。
Airflow是一个基于Python开发的,通过编程的方式创建、调度和监控工作流(workflow)的平台。最早由Maxime Beauchemin于2014年10月在Airbnb创建,并且从创建之初就以开源的形式开发。2016年3月进入Apache基金孵化器,2019年1月正式成为Apache顶级项目。
官方文档中,特意强调了使用代码定义工作流的优点,使得工作流的维护、版本管理、测试和协作变得更加容易,直接复用代码开发过程中用到工具、系统就可以了,无需再重复造轮子,可以像开发软件系统一样开发数据任务,持续集成也是开箱即用。但是数据任务的测试向来不是一件简单的事情,不知道在实际使用中基于Airflow的数据开发CI/CD流畅度如何。这种基于Python代码定义工作流的方式使用门槛稍微高了一点。基于代码定义flow中节点的依赖关系,并不如通过界面拖拽那么直观,是不是也会使易用性大大折扣?
架构
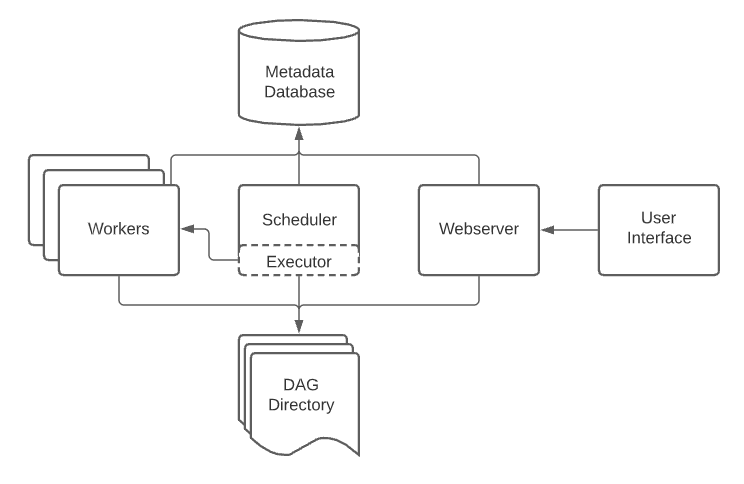 如上图所示,Airflow主要由以下几个部分组成:
如上图所示,Airflow主要由以下几个部分组成:
DAG目录(DAG Directory)
存储定义DAG的Python文件的目录,调度器、执行器和执行节点会读取该目录下的文件获取DAG相关信息,所以要确保所有节点上DAG目录的数据同步。如何确保文件同步到也是一项复杂的工程。
数据库(Metadata Database)
数据库主要用于存储系统的配置信息(系统变量,数据源链接信息,用户信息等)、解析DAG文件生成的DAG对象和任务执行的状态等信息。
调度器(Scheduler)
独立部署的进程,负责触发执行定时调度的工作流。调度器主要负责两件事:1)定时扫描DAG文件目录,解析变更或新增的DAG文件,并将解析后生成的DAG对象(Serialized DAG)存储到数据库;2)扫描数据库中的DAG对象,如果满足调度执行条件,则触发生成任务实例并提交给Executor执行。
调度器高可用
从2.0开始,Airflow调度器支持高可用部署,采用了我之前实现调度服务高可用时使用的策略,通过数据库行锁的机制,实现多主的高可用。这样实现的好处是减少了leader选举、节点故障转移的复杂度。多个节点同时工作相较于主从模式也能获取较好的处理性能,可以通过横向扩展调度器提升调度服务的处理能力,但终究要受限于底层单点数据库的处理能力。如果执行事务的时长比较久,特别是事务中存在校验并发限制、资源使用配额的操作时,就很容易造成死锁,所以在Airflow实际部署中,高可用对数据库有着特殊的要求,需要数据库支持SKIP LOCKED或者NOWAIT。
执行器(Executor)
执行器负责执行或者提交执行任务实例(Task Instances)。执行器在实际部署中集成在调度器进程内,Airflow提供了两种类型的执行器,1)本地执行器,任务直接在调度器所在节点上执行;2)远程执行器,根据各执行器的实现方式,将任务提交到远程执行节点上执行。如果系统自带的执行器无法满足你的业务需求,可以自行实现自定义执行器。
系统自带本地执行器:
- Debug Executor: 主要用于在IDE中对任务进行测试执行。
- Local Executor:在调度器本地新建进程执行任务实例,可以通过
parallelism参数控制最大任务并发数。 - Sequential Executor: 可以理解为最大并发数1的Local Executor。
系统自带远程执行器:
- Celery Executor:Celery是一个基于Python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理。Celery Executor将任务发送到消息队列(RabbitMQ, Redis等),然后 Celery Worker 从消息队列中消费执行任务,并将执行结果写入到Celery的Backend中。Celery Executor 通过队列(queues)实现资源隔离,定义任务时指定使用的具体队列,则该任务只能由相应队列的worker执行。但是这个资源隔离的粒度有点粗,如果想实现更细粒度的资源,可以选择 Kubernetes Executor。
- Kubernetes Executor: 通过K8S集群执行任务。Kubernetes Executor调用K8S API申请Worker Pod,然后由Pod负责任务的执行。
- CeleryKubernetes Executor:是上面两个执行器的组合,因为Airflow部署时只能指定一种类型执行器,如果既需要通过Celery执行又想提交到K8S集群执行,则可以选择该执行器。
- Dask Executor: Dask是基于Python实现的分布式计算框架,Dask Executor主要是通过Dask分布式集群执行任务。
远程执行时所有执行节点都会直接数据库,鉴于弹性伸缩是Airflow的一大特性,如果执行节点规模太大对数据库造成的压力不可小觑,所以为什么要采用执行节点直连数据的方式呢?
执行节点(worker)
负责具体任务的执行,根据执行器不同,可能是调度器所在节点,Celery Worker节点,K8S Pod等。
WebServer
WebServer主要为用户提供了管理DAG(启用、禁用,手动执行),查看和操作DAG的执行状态,管理系统权限,查看和修改系统配置,管理数据源等功能。前文提到的通过代码定义依赖关系不直观的问题,Airflow在WebServer给了解决方案,运行DAG,然后通过WebServer的Graph视图以可视化的方式展示DAG。如果一定要在执行前可视化的方式查看DAG也可以在命令行执行airflow dags show生成Graph视图的图片。也许是我调研的还不够深入,难道就没有实时可视化展示DAG的方案?
功能特性
工作流定义

Airflow通过Python代码以DAG的形式定义工作流,以下代码片段定义了上图由7个任务节点组成的DAG。
// 从2021年1月1日开始,每天零点调度
with DAG(
"daily_dag", schedule_interval="@daily", start_date=datetime(2021, 1, 1)
) as dag:
ingest = DummyOperator(task_id="ingest")
analyse = DummyOperator(task_id="analyze")
check = DummyOperator(task_id="check_integrity")
describe = DummyOperator(task_id="describe_integrity")
error = DummyOperator(task_id="email_error")
save = DummyOperator(task_id="save")
report = DummyOperator(task_id="report")
ingest >> analyse // 通过`>>`,`<<`定义节点依赖关系
analyse.set_downstream(check) // 通过`set_downstream`,`set_upstream`定义节点依赖关系
check >> Label("No errors") >> save >> report // 通过`Label`注释依赖关系
check >> Label("Errors found") >> describe >> error >> reportDAG由节点、节点间的依赖关系以及节点间的数据流组成。节点的类型主要有以下三种:
- Operator: 任务节点,负责执行某种类型的任务。Airflow和社区已经实现了大量的Operator,基本覆盖了常用数据库,Hadoop生态活跃的系统和服务,以及AWS、Google和Azure三大海外云平台的系统和服务。
- Sensor: 一种特殊的Operator,主要用来监听外部事件,可用作对外部系统、数据的依赖。Airflow通过
external_taskSensor实现了DAG任务间的依赖。 @task注解的Python函数,可以理解为基于Python装饰器定义的语法糖,能快速简洁的定义PythonOperator。
如以上Python代码所示,节点间的依赖关系可以通过位操作符>>/<<或set_upstream/set_downstream方法定义。
默认情况下下游节点要等上游所有节点执行成功后才开始执行,Airflow提供了多种方式来改变这一默认行为。第一种方式就是通过自定义节点的触发规则(Trigger Rules)。Airflow提供了上游所有节点都失败、所有节点执行完成、部分节点失败、部分节点成功等多种规则,详情参考上述链接。另一种方式就是通过控制节点。目前有三种控制节点可以改变默认行为:
- 分支节点(Branching): 通过
python_callable函数返回的task_id决定执行下游哪个节点。 - 仅执行最新节点(Latest Only): 如果
仅执行最新节点当前所属的DAG执行实例,不是改DAG最新的执行实例,则改节点及其所有子节点都不会被执行。 - 自依赖节点(Depends On Past): 依赖节点的上一次执行,只有上一次DAG调度中该节点执行成功了,才触发这一次执行。
除了定义节点间的依赖关系,Airflow还通过XComs(cross-communications)实现了节点间的数据流。节点可以通过xcom_push方法输出数据,其他节点可以通过xcom_pull方法获取节点的输出数据。
调度
定时调度是通过DAG的schedule_interval参数定义,传参可以是datetime.timedelta对象、cron表达式(Unix格式)或者@daily、@monthly等预设cron表达式。对于任务调度时间的定义,Airflow采用了目前我所接触到的任务调度系统中不同的视角,用数据时间(Airflow称它为logical date,有的系统称它为etl_date)来定义任务调度时间。举个例子,假如DAG配置每天调度一次,在Airflow中2021-12-26这次的调度实例,要在2021-12-27这天凌晨才会生成,处理的是2021-12-26的数据。而在其他系统中2021-12-26这次的调度实例就是在2021-12-26生成,处理的是2021-12-25的数据。
针对MissFire策略(概念来自quartz),Airflow提供了catchup参数。如果catchup设置为false,则未生成的调度时间段直接跳过,只生成最新的调度实例。另外在禁用和启用调度DAG后catchup逻辑也会触发。
超时失败和报警
如果要限制节点最大执行时间,可以设置execution_timeout参数,节点在execution_timeout配置时间内未执行成功则自动超时失败。任务执行超时报警是通过sla参数配置的,节点在sla指定的时间内没有执行成功,系统自动发送SLA未满足邮件,也可以通过sla_miss_callback回调函数,自定义任务超时的逻辑。
关于报警,Airflow提供了email_on_failure,email_on_retry参数控制节点在执行失败、重试时是否发送邮件报警。在实际生产环境中,邮件报警肯定是不能满足需求的,其他报警方式可以通过自定义on_failure_callback,on_retry_callback回调函数实现。
并发限制
Airflow提供了多种粒度的并发限制。
系统级别
parallelism: Airflow并发执行的任务数max_active_runs_per_dag: 每个DAG可并发生成的DAG调度实例数dag_concurrency: 每个DAG实例并发执行的任务数worker_concurrency: 每个执行节点可并发执行的任务数,仅 Celery Executor 的执行节点支持该配置
DAG级别
max_active_runs: 当前DAG可并发生成的DAG调度实例数,该配置会覆盖系统级别的max_active_runs_per_dagconcurrency: 当前DAG实例并发执行的任务数,该配置会覆盖系统级别的dag_concurrency
任务级别
pool:pool是Airflow用于实现跨DAG、跨任务的并发限制方案。定义任务时指定任务所属pool、任务使用的slot数、任务优先级;pool资源使用达到上限后,所有隶属该pool的任务实例进入排队状态,有空闲资源释放时,高优先任务优先获取资源。资源分配的具体策略这里就没有在深入研究。task_concurrency:当前任务节点的最大并发执行实例个数,类似于max_active_runs,只是粒度更细
补数据和手动执行
补数据(backfill)可以通过以下命令触发:
airflow dags backfill --start-date START_DATE --end-date END_DATE dag_id默认情况下,补数据只生成并执行指定时间范围内缺失的调度记录。再举个例子,DAG每天调度一次,现在要补2021-12-01到2021-12-03之间的数据,其中2021-12-02这天已经调度执行过,则补数据任务只会创建执行2021-12-01和20210-12-03的调度记录。backfill命令提供了多种选项来覆盖这一默认策略。
手动执行可以通过命令airflow dags trigger --exec-date logical_date run_id或者通过WebServer触发。
数据血缘
本着让专业的人干专业的事的理念,Airflow依托于第三方元数据管理系统实现数据血缘管理,平台本身只实现血缘的搜集和上报。通过任务的inlets和outlets属性定义任务的血缘信息,血缘信息在任务的post_execute方法中推送到XCOM,然后再由LineageBackend把血缘信息写到Atlas、DataHub(WhereHows)或者自定义的元数据管理系统。
总结
本文通过官方文档和网上相关资料,“纸上”静态地调研了Airflow的系统架构和功能特性。整体而言,Airflow是一个调度功能完善、扩展伸缩性良好、文档详尽、社区强大活跃的工作流调度平台。个人感觉在任务调度系统选型上,可能阻碍Airflow入选的最主要因素是基于Python技术栈实现的整个系统和DAG定义。如果负责平台的同学和系统面向的用户有Python相关技术背景,从纸面上看,Airflow是个非常不错、甚至是第一优先级的选择。
参考资料
Apache Airflow Documentation
The Airflow 2.0 Scheduler
Scaling Out Airflow
The Airflow UI