
本文将主要介绍Kubernetes集群中各个组件的工作原理(非源码级别),以帮助大家更深入的了解K8S,从而更高效地使用K8S。由于本篇不是入门级文章,需要大家对K8S有些基本的了解,知道它提供了哪些功能,才能更好地理解这篇文章。如果还不了解K8S的功能特性,可以参考这篇一起学习k8s做个快速入门。
架构
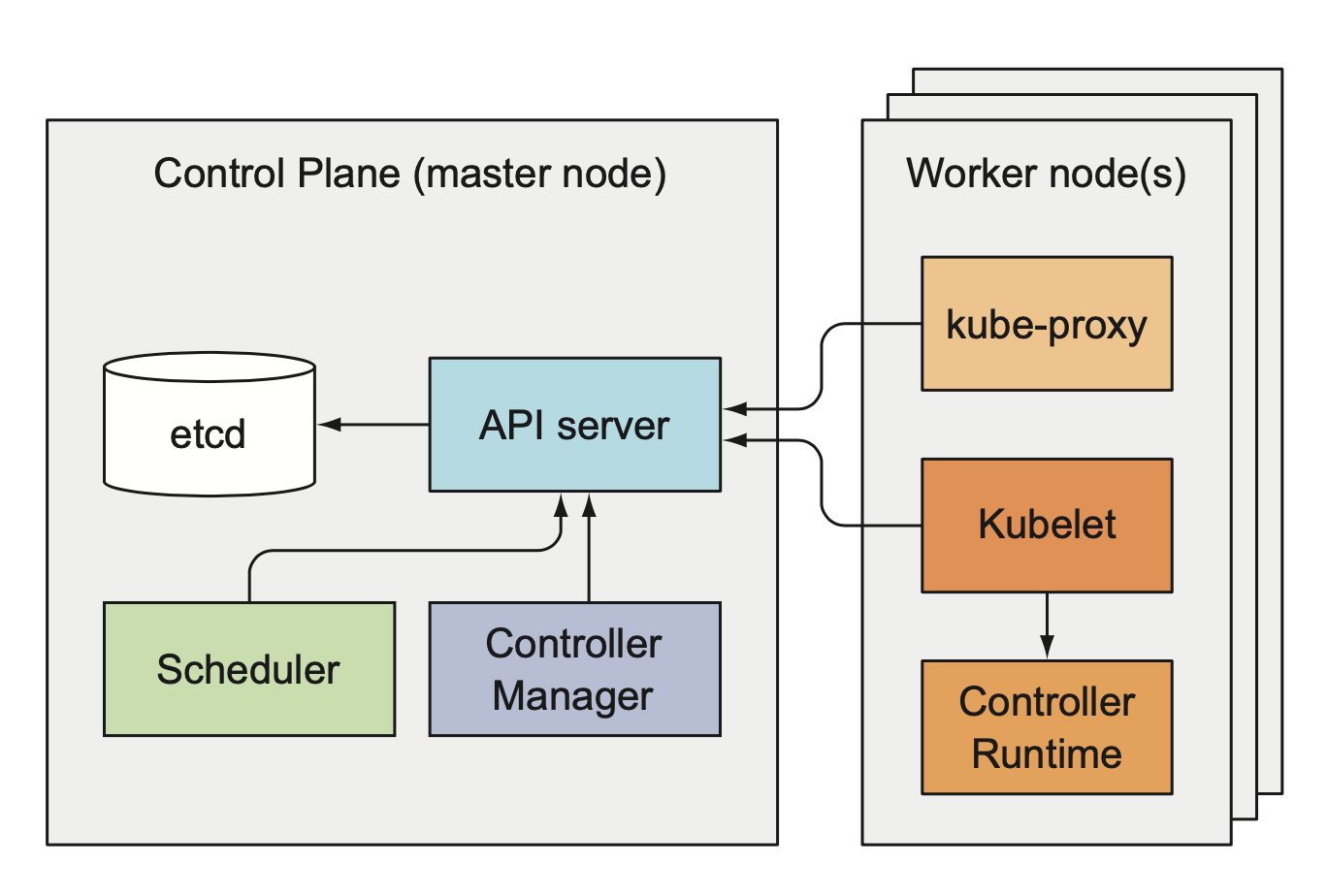
作为资源管理和调度系统,K8S集群的整体架构跟yarn或mesos都有着异曲同工之处。K8S集群主要有两种角色的节点组成:主节点(Control Plane)和工作节点。主节点主要负责存储、管理集群的状态,同时向客户端提供访问集群的接口;工作节点则主要负责执行、监控客户端通过主节点提交的容器化应用。
主节点
主节点在K8S集群里只是个逻辑上的概念,实际部署中它是由多个独立部署、各司其职的组件共同组成,这些组件也并非一定要部署在同一台机器上。主节点主要由以下组件组成:
- etcd
- API Server
- 调度器(Scheduler)
- 控制器(Controller Mananger)
etcd
etcd是基于raft一致性算法实现的高可用键值存储系统,主要用于共享配置和服务发现,类似于Hadoop生态圈的Zookeeper。etcd在K8S集群的作用是持久化集群的状态和元数据信息。通过K8S接口创建的各种资源信息(Pods, ReplicationControllers, Services等)及其状态都存储在etcd。资源在etcd的存储结构大概是这个样子:
/registry/configmaps
/registry/daemonsets
/registry/deployments
/registry/events
/registry/namespaces
/registry/pods
...
K8S集群的所有组件中,唯一跟etcd交互的组件是API Server,其他组件或者客户端需要查询、变更集群状态时都需要通过调用或者监听API Server提供的接口。这样设计的好处是:1)统一变更集群状态的入口,在入口处做统一的鉴权和校验,从而保证系统状态的一致性;2)封装底层存储的细节,如果哪天心血来潮想换个存储方案,其他组件和客户端则不需要做任何调整。
API Server
如上文提到的那样,API Server是其他组件和客户端跟K8S集群交互的统一入口。它对外提供了用于查询和变更集群状态的RESTful API。这些API会对客户端请求进行鉴权并校验提交资源合法性,以保证系统安全和集群状态的稳定性。鉴权的方式和校验资源合法性的规则都可以通过插件的形式自行扩展。API Server 同时采用了乐观锁来保证在并发更新情况下资源状态的一致性。
下文将要提到的调度器和资源管理器都需及时感知到集群系统状态的变更然后做出相应的响应,如果通过轮询的方式定时查询集群状态势必会给API Server造成巨大的压力。API Server提供了一种监听机制(watch),客户端可以通过HTTP接口监听自己关注的资源变更事件,一旦有相关变更API Server就会向客户端发送相应的事件信息。
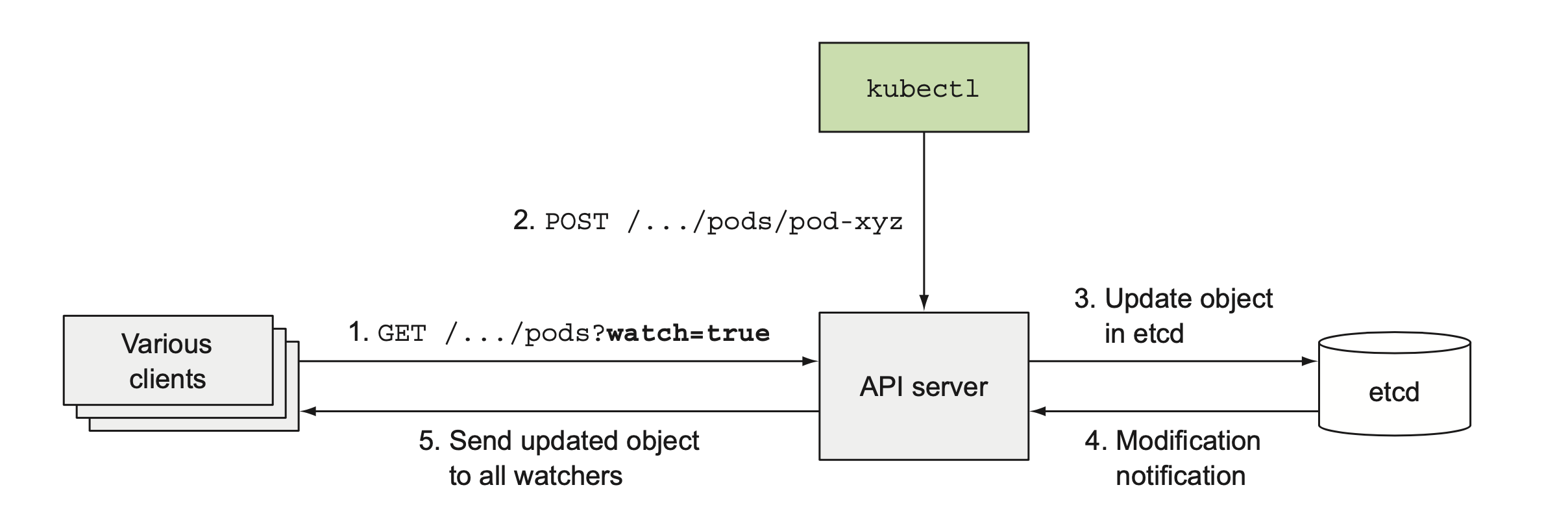
监听机制理论上应该基于TCP长连接实现才最有效,虽然HTTP协议可以通过
Connection keep-alive实现多个HTTP请求复用同一个TCP连接,但针对单次HTTP请求来说还是一次短连接,那么K8S是如何通过HTTP实现监听的呢?可以参考下这篇文章
统一集群交互入口的优点在介绍etcd时提到了,但是这种类似于服务总线的中心化设计使得API Server成为整个系统的单点,一旦出现故障会导致整个集群都不可用。好在API Server是无状态的,支持灵活地横向扩展,持久化集群状态的etcd也支持分布式部署,但是由于etcd并不支持分片,这可能是限制K8S集群规模的制约点。
调度器
调度器的工作其实很简单,通过API Server监听所有未分配节点的Pod,然后给这个Pod分配一个合适的工作节点,并把分配到节点写入到Pod的配置信息里。余下的容器创建和监控工作就由分配到的节点来完成了。
不过选择节点过程并不像一句“分配一个合适的节点”描述的那么简单,默认调度器选择节点大致分为两个步骤:首先筛选出所有满足Pod需求的节点,然后再在这些节点中选择一个最优的节点,如果有多个最优,则通过轮询(Round-robin)的方式在其中选择一个。筛选节点的条件如下:
- 是否满足Pod的硬件资源要求(内存、CPU等)
- 是否有剩余资源
- 如果Pod指定了节点,当前节点是否是指定节点
- 节点标签是否满足Pod的node selector
- Pod要绑定的端口在该节点上是否被占用
- Pod指定挂载的卷能否在节点上挂载
- Pod是否能容忍节点的污点(taints)
- Pod调度到该节点上是否满足pod的亲和性与非亲和性(affinity or anti-affinity)要求
调度器很难通过一套普适算法满足所有的需求,所以K8S支持部署多个调度器,可以在Pod通过设置schedulerName指定需要使用的调度器,如果不指定则使用默认调度器。如果系统提供的调度器不能满足需要,可以自行实现并部署到集群。
控制器
控制器由多个相互独立Controller组成,每个Controller负责管理跟它绑定的资源,确保它所管理的资源维持在既定状态。这个描述可能有点抽象,通过下面对各Controller功能介绍能更直观地了解它们的作用。
REPLICATION MANAGER
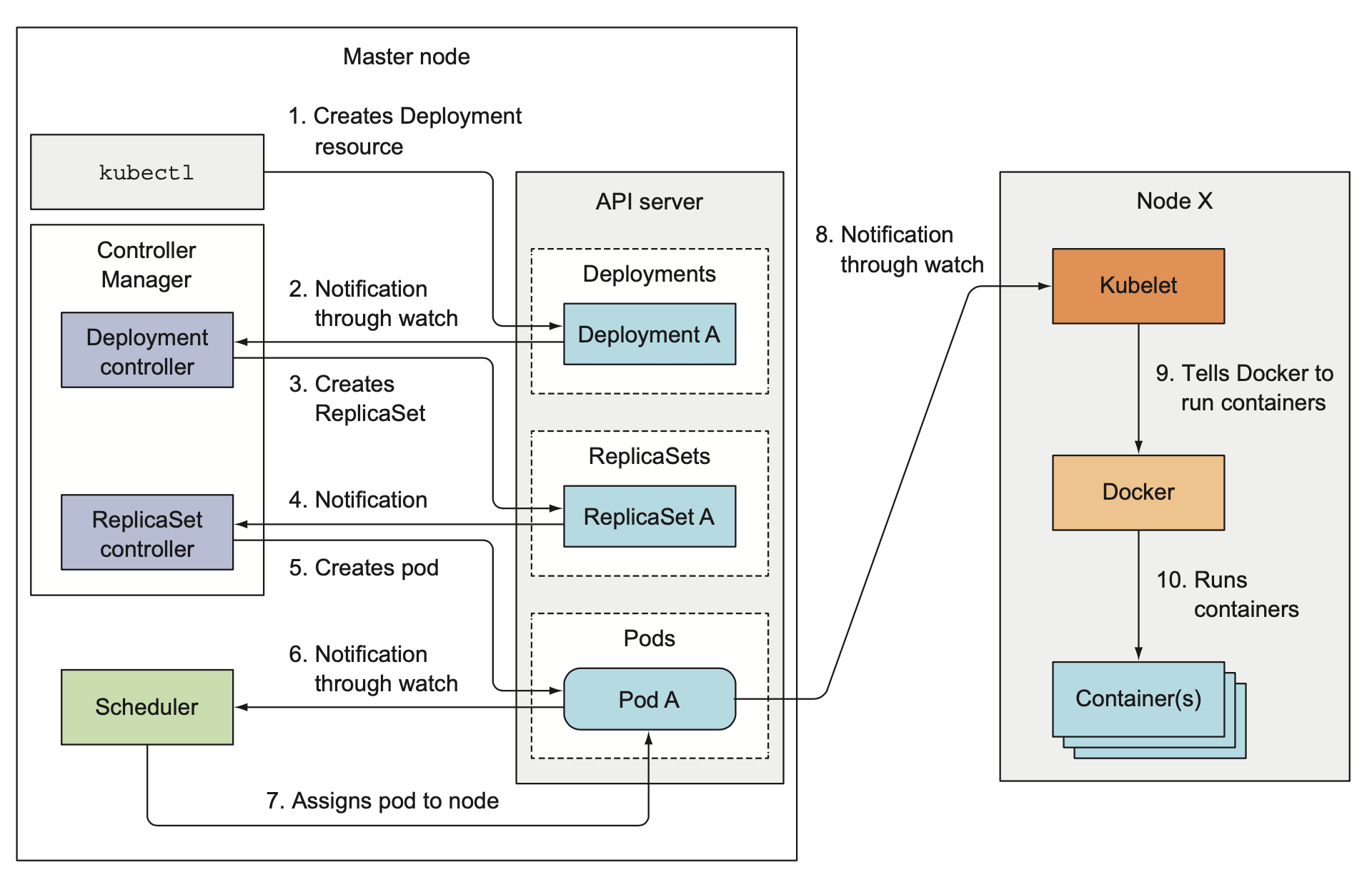
Replication Manager负责管理资源ReplicationController,确保运行中的Pod副本数满足ReplicationController的定义。它通过API Server监听ReplicationController及其管理的Pod信息,如果Pod副本数不满足,则调用接口新建或删除Pod,其他controller的工作原理也都类似。新建Pod时Replication Manager并不直接运行Pod,而是像其他客户端一样往API Server提交一条创建Pod请求,然后由Scheduler给该Pod分配节点,再由工作节点启动相应的container。
REPLICASET,DAEMONSET,JOB CONTROLLER
分别负责管理ReplicaSet,DaemonSet和Job资源,监听相应资源信息,根据资源里Pod模板创建Pod。
DEPLOYMENT CONTROLLER
负责管理Deployment资源。每次Deployment被修改时,Deployment Controller都会创建一个新的ReplicaSet版本,然后根据Deployment中定义的策略,逐渐调整新老ReplicaSet的副本数,直到新版本完全替换掉老版本。
STATEFULSET CONTROLLER
作用跟REPLICASET CONTROLLER类似,根据StatefulSet的配置调整Pod,不同的是它还负责初始化和管理Pod实例的PVC(PersistentVolumeClaims)
NODE CONTROLLER
负责维护集群的节点列表信息,监控节点的健康状况,将Pod从不可用节点上删除。
SERVICE 和 ENDPOINTS CONTROLLER
Service controller 监听Service资源的变更,创建或删除相应的Service。Endpoints controller 则同时监听Services和Pod资源信息,根据相应的变更更新Endpoints(IP+端口),并在Service被删除时删除对应的Endpoints。
NAMESPACE CONTROLLER
Namespace Controller功能相对简单,负责在namespace被删除时,删除该namespace下所有的资源。
PERSISTENTVOLUME CONTROLLER
PersistentVolume Controller主要负责给PVC绑定/解绑PersistentVolume。
Controller间的协作
Controller彼此之间没有直接依赖,甚至感知不到彼此的存在,但是它们管理的资源是存在依赖关系的,这种依赖关系通过总线API Server在Controller间传递,以此实现Controller间的协作。以Deployment为例,它依赖于ReplicaSet创建Pod。当客户端向API Server提交Deployment时,Deployment Controller根据配置创建ReplicaSet,Replica Controller监听到ReplicaSet事件后创建Pod,然后由Scheduler调度Pod到指定节点,再由Kubelet启动执行Pod。
调度器和控制器的高可用
调度器和控制器的执行逻辑是典型的checkAndSet,如果check和set操作不能原子性地完成(监听API Server事件然后做出响应不能原子性地完成),在并发情况下会造成数据不一致,这就限制了调度器和控制器的横向扩展。为了保证调度器和监控器的高可用,K8S默认采用热备份的方式部署多个调度器和控制器实例,通过leader选举的方式选举master节点,由master节点来处理调度和控制管理工作,其他实例在master故障后竞争成为master来接管调度工作。
K8S通过更新Endpoints或者ConfigMaps资源实现leader选举,成功更新该资源的客户端获取leader角色,并定时上报心跳以维持自己的leader角色,如果leader失联或者心跳超时,其它客户端开始发起更新请求竞争成为leader角色。考虑到K8S应用也有像调度器和控制器这样无法很容易实现横向扩展但又需要保持高可用的需求,K8S集群提供了开箱即用的leader选举功能,具体使用和细节可以参考这篇文章。
工作节点
工作节点的组成相对简单,由Kubelet和Kubernetes Service Proxy组成,并且这两个组件需要同时部署在同一节点上。
Kubelet
Kubelet主要负责执行、监控由调度器分配的Pod。Kubelet启动后会向API Server注册一个Node资源,并定时上报节点的信息。随后通过监听API Server获取分配到当前节点的Pod,拉取Pod使用的镜像并启动容器,然后定时上报容器的运行状态、事件和资源使用信息到API Server。
Kubelet在启动Pod中定义的容器同时还会启动一个特殊的pause容器(该容器的状态一直是Pause),又叫Infra容器。它的作用是为了保证Pod中所有的容器都共享同一个namespace(比如共用同一个IP地址)。在创建其他容器前,Kubelet先创建Pause容器,然后再创建其他容器并加入Pause容器的namespace,在容器发生重启时同样会再次加入Pause容器的namespace。
Kubelet除了通过监听API Server获取Pod任务外,还可以通过监听HTTP接口或者本地路径获取Pod并执行、更新之。通过这种方式可以实现由Kubelet运行和管理主节点的所有组件,在一定程度实现编程语言里的自举。
Kubernetes Service Proxy(kube-proxy)
kube-proxy的作用是当客户端调用Service的虚IP和端口访问Service时,确保该请求可以被成功地转发到Service管理的Pod中去,如果Service由多个Pod组成,kube-proxy还要保证在Pod间做好负载。K8S集群网络问题相对比较复杂,打算单独放在一篇文章里介绍,敬请期待。
参考
- Kubernetes in Action
- Pause容器