
Netflix 目前拥有公有云上最复杂的数据平台之一,数据科学家和数据开发工程师在该平台上每天运行着大量批处理和流处理任务。随着我们的付费订阅用户在全球范围内的增长以及Netflix 正式进入游戏赛道,批、流处理任务的数量也迅速增加。我们的数据平台基于诸多分布式系统构建而成,由于分布式系统的固有特性,运行在数据平台上的任务不可避免地隔三差五出现问题。对这些问题进行定位分析是件很繁琐的事,涉及从多个不同系统收集日志和相关指标,并对其进行分析以找出问题的根本原因。在我们当前规模上,如果人工手动地定位和解决问题,即使是处理一小部分异常任务,也会给数据平台团队带来巨大的运维负担。另外,这种手动定位问题的方式,对平台用户工作效率上造成影响也不可小觑。
以上问题促使我们尽可能主动地检测和处理生产环境中的失败任务,尽量避免使团队工作效率降低的异常。于是我们在数据平台中设计、开发了一套名为 Pensive 的自动诊断和修复系统。目标是对执行失败和执行时间过长的任务进行故障诊断,并尽可能在无需人工干预的情况下对其进行修复。随着我们的平台不断发展,不同的场景和问题(scenarios and issues)都可能会造成任务失败,Pensive 必须主动在平台级别实时检测所有的问题,并诊断对相关任务的影响。
Pensive 由两个独立的系统组成,分别支持批任务和流任务的自动诊断。本文将简单介绍这两个系统的功能,以及它们是如何在离线平台(Big Data Platform)和实时计算平台(Real-time infrastructure)中执行自动诊断和修复。
批任务自动诊断系统 - Batch Pensive
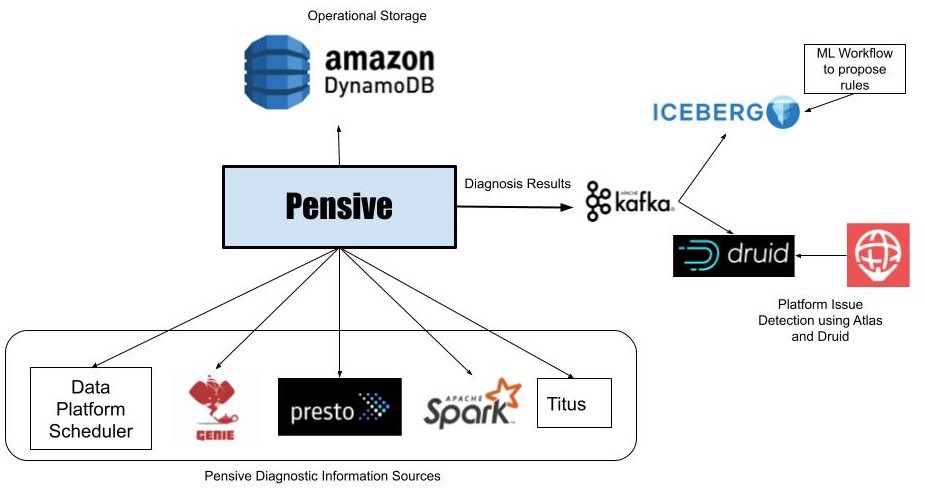 图1: 批任务自动诊断系统架构图
图1: 批任务自动诊断系统架构图
数据平台中的批处理工作流任务使用Netfix 自研的调度服务 Meson 调度执行,调度服务通过启动容器运行工作流节点,容器则运行在Netflix 自研的容器管理平台 Titus 上。这些工作流节点通过 Genie(类似Apache Livy) 提交执行 Spark 和 TrinoDb 作业。 如果工作流节点失败,调度服务会向 Pensive 发送错误诊断请求。Pensive 从相关数据平台组件中收集该节点执行过程中产生的失败日志,然后提取分析异常堆栈。Pensive 依赖于基于正则表达式的规则引擎来进行异常诊断,这些规则是在不断的实践中总结归纳出来的。系统根据规则判定错误是由于平台问题还是用户Bug造成的、错误是否是临时抖动造成的(transient)。如果有个一条规则命中错误,Pensive 会将有关该错误的信息返回给调度服务。如果错误是临时抖动造成的,调度服务将使用指数退避策略(exponential backoff)重试执行该节点几次。
Pensive 最核心的部分是对错误进行分类的规则。随着平台的发展,这些规则需要不断被完善和改进,以确保 Pensive 维持较高的错误诊断率。最初,这些规则是由平台组件负责人和用户根据他们的经验或遇到的问题而贡献的。我们现在则采用了更系统的方法,将未知错误输入到机器学习系统,然后由机器学习任务对这些问题进行聚类,以针对常见错误归纳出新的正则表达式。我们将新正则提交给平台组件负责人,然后由相关负责人确认错误来源的分类以及它是否是临时抖动性的。未来,我们希望将这一过程自动化。
检测平台级别的问题
Pensive 可以对单个工作流节点的失败进行错误分类,但是通过使用 Kafka 和 Druid 对 Pensive 检测到的所有错误进行实时分析,我们可以快速识别影响所有工作流任务的平台问题。单个失败任务的诊断被存储在 Druid 表中后,我们的监控和警报系统 Atlas 会对表中的数据每分钟进行一次聚合,并在因平台问题导致任务失败数量突增时发送告警。这大大减少了在检测硬件问题或新上线系统中的Bug所需的时间。
流任务自动诊断系统 - Streaming Pensive
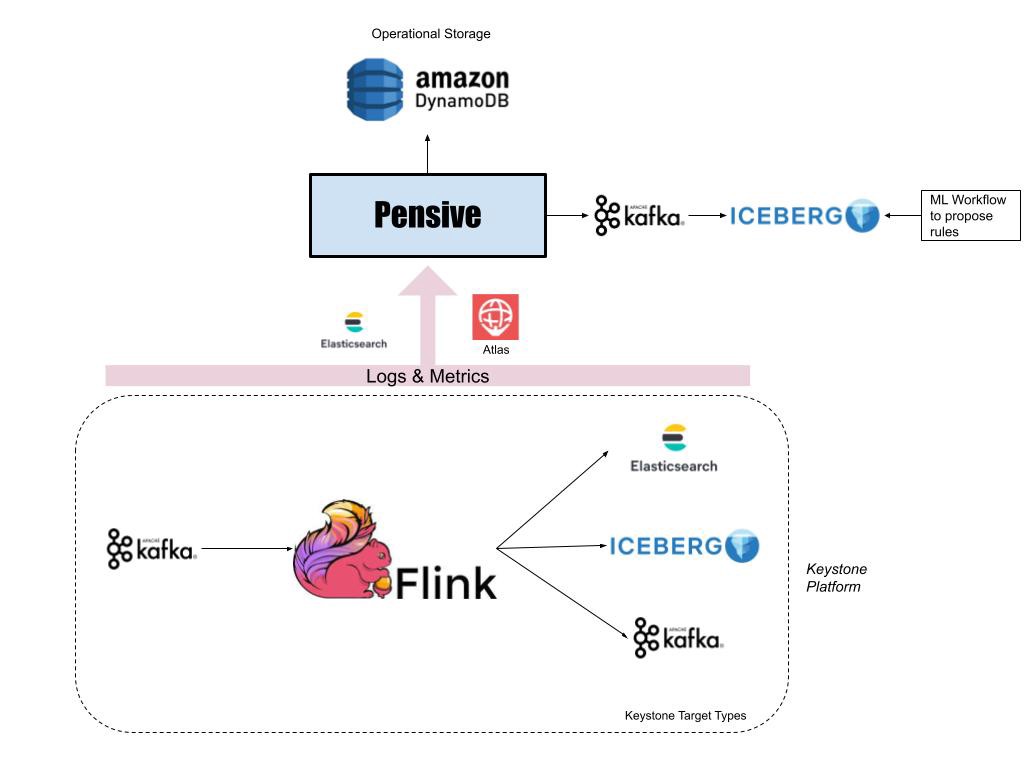 图2: 批任务自动诊断系统架构图
图2: 批任务自动诊断系统架构图
Netflix 数据平台中的实时计算基于Apache Flink实现。大多数 Flink 任务运行在 Keystone 流任务处理平台上,该平台封装了底层 Flink 任务详细信息,给用户提供了消费 Kafka 消息和将处理结果写入到不同数据存储系统(如AWS S3 上的ElasticSearch 和 Iceberg)的能力。
由于数据平台管理着 Keystone 的数据处理流程,用户希望 Keystone 团队能够主动检测和修复平台问题,而无需他们的任何参与。此外,由于 Kafka 中的数据一般不会长期存储,这就需要我们及时地、在数据过期之前解决问题。
对于运行在 Keystone 上的每个 Flink 任务,我们会监控消费者的滞后程度(lag)指标。如果超过阈值,Atlas会向 Streaming Pensive 发送通知。
与批任务诊断系统一样,Streaming Pensive 也是基于规则引擎来诊断错误。但是,除了日志之外,Streaming Pensive 还会检查 Keystone 中多个组件的各种指标。错误可能出现在任何一个组件中,如源头的Kafka 、Flink 任务或者 Sink 端数据存储系统。Streaming Pensive 对这些日志和指标进行诊断,并尝试在问题发生时自动修复。我们目前能够自动修复的一些场景如下:
- 如果 Streaming Pensive 发现一个或多个 Flink Task Manager 内存不足,系统可以增加 Task Manager 数重新部署 Flink 集群。
- 如果 Streaming Pensive 发现 Kafka 集群上的写入消息速率突然增加,它可以临时增加topic数据保留的大小和保留时间,这样我们就不会在消费者滞后时丢失任何数据。如果峰值在一段时间后消失,Streaming Pensive 可以自动恢复到之前的配置。否则,它将通知任务负责人,排查是否存在导致写入速度突增的错误,或者是否需要重新调整消费者以处理更高的写入速度。
尽管我们的自动诊断成功率很高,但仍然存在无法实现自动化的情况。如果需要人工干预,Streaming Pensive 将通知相关组件团队,以便及时采取措施解决问题。
未来规划
Pensive 对 Netflix 数据平台的日常运行至关重要。它帮助工程团队减轻运维负担,让他们专注于解决更关键和更具挑战性的问题。但我们的工作还远未完成,未来还有很多工作要做。以下是我们未来的规划:
- Batch Pensive 目前仅支持诊断失败的任务,我们希望后续扩展支持任务性能诊断以确定任务执行变慢的原因。
- 自动配置批处理工作流任务,以便它们能成功执行或快速且高效的执行。其中一个方向是 Spark 任务内存自动调优,是一项颇具挑战性的工作。
- 使用机器学习分类器来完善 Pensive(的规则)。
- 实时计算平台最近上线了Data Mesh功能,我们需要扩展 Streaming Pensive 来支持该功能的诊断。
致谢
感谢 Netflix 数据平台的离线计算团队和实时计算团队的帮助和支持,如果没有他们这项工作是无法完成的。在我们致力于改善 Pensive 的过程中,他们一直是我们的坚实的支柱。
原文链接: Auto-Diagnosis and Remediation in Netflix Data Platform